
Improving RL using LLMs
Published:
What are different ways in recent research in which LLMs can help improve Reinforcement Learning?
Introduction
Reinforcement Learning (RL) agents typically rely on random exploration during the early stages of training. They take actions in an environment, observe rewards, and gradually optimize their policies. This process works reasonably well in simple tasks, but breaks down when:
- Rewards are sparse,
- Action spaces are large or combinatorial, or
- The environment is highly complex.
In such cases, trial-and-error exploration wastes time on illogical or useless actions. For instance, in a Minecraft-like world, an RL agent might try both “Eat Cow” and “Drink Cow”. In a household simulation, it might attempt to “Put Coffee in Microwave” before picking it up.
Crafter: an open world survival game

VirtualHome: a multi-agent platform to simulate activities in a household
Humans avoid such mistakes because we possess common sense. We know which actions are meaningful, safe, or sequentially valid. RL agents, however, lack this implicit prior knowledge, resulting in undirected exploration and painfully slow learning.
This is where Large Language Models (LLMs) come in.
Why LLMs Can Help RL
LLMs encode a vast amount of structured and unstructured world knowledge, ranging from everyday commonsense to specialized domains. Integrating them into RL can provide:
- Guidance in exploration (avoid illogical actions, prioritize promising ones).
- Planning abilities (breaking tasks into sub-goals).
- Reward shaping (offering dense feedback signals).
- Curriculum learning (progressively harder tasks).
- Interpretability (natural language rationales that explain agent behavior).
By leveraging these properties, RL agents can bootstrap learning more efficiently, even in sparse or complex environments.
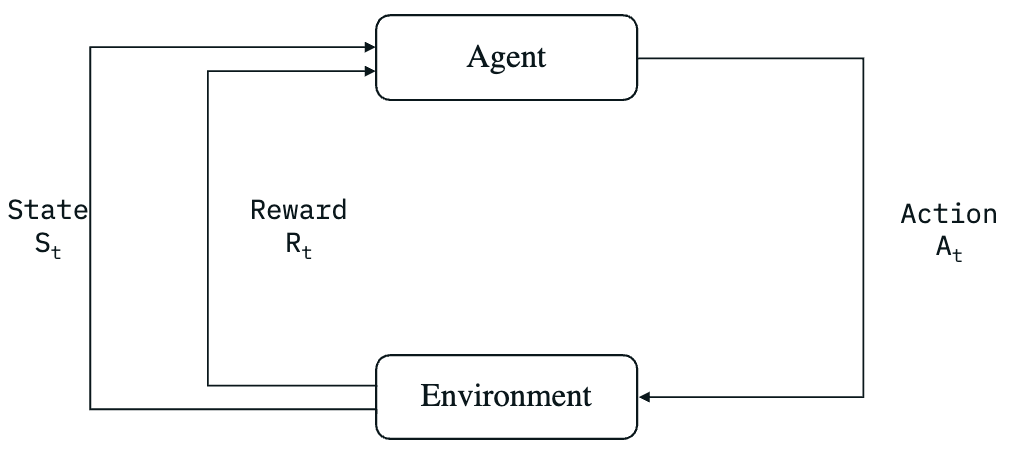
Basic components in a basic RL training pipeline
Recent Approaches
Here are some promising directions explored in recent research:
1. LLMs as Information Processors
LLMs can enhance the agent’s observation by adding implicit knowledge and real-world priors. This includes compressing the trajectory history using LLMs (Paischer et al., 2022) or encoding observations into natural language (Paischer et al., 2023). These methods also address partial observability in many environments by introducing a memory component into the observation.
2. LLMs as Reward Models
LLMs as Reward Models can help designing the reward function in scenarios where the reward function is not easily available. For example, (Kwon, Minae, et al., 2023) used the LLMs to evaluate whether a trajectory of text-based games exhibits a certain behaviour, and rewards the agent if it does. This opens a door to training preference aligned policies with as minimal human input as defining the desired behaviour. In an another work, (Du, Yuqing, et al., 2023) used the LLM to suggest the next sub-goal and reward the agent if it achieves the sub-goal.
3. LLMs as Planners
LLMs can generate loose, high-level plans that follow a common-sense chain of thought, which a low-level RL policy can then follow. (Ahn, Michael, et al., 2022) used LLMs to generate such plans as sub-goals, which were combined with an affordance function that scores each sub-goal based on its viability in the current state. The agent follows this plan, which is dynamically updated as it interacts with the environment.
4. LLMs as Policies
LLMs can directly take—or assist in taking—the next action. (Li, Shuang, et al., 2022) initialized the policy function with a pre-trained language model and added an action-prediction layer. When trained in a household environment, the agent achieved state-of-the-art performance by leveraging the LLM’s pre-trained knowledge.
Conclusion
Reinforcement Learning alone struggles in environments with sparse rewards and complex action spaces. Large Language Models offer a powerful complement: they bring commonsense priors, planning ability, and interpretability to the table.
As the field evolves, hybrid systems combining LLMs and RL may unlock agents that are both more sample-efficient and more aligned with human reasoning.
The key question now is: How do we design RL pipelines that balance the strengths of LLMs with the adaptability of traditional learning?
References:
Paischer, Fabian, et al. “History compression via language models in reinforcement learning.” International Conference on Machine Learning. PMLR, 2022.
Paischer, Fabian, et al. “Semantic helm: A human-readable memory for reinforcement learning.” Advances in Neural Information Processing Systems 36 (2023): 9837-9865.
Kwon, Minae, et al. “Reward design with language models.” arXiv preprint arXiv:2303.00001 (2023).
Du, Yuqing, et al. “Guiding pretraining in reinforcement learning with large language models.” International Conference on Machine Learning. PMLR, 2023.
Ahn, Michael, et al. “Do as i can, not as i say: Grounding language in robotic affordances.” arXiv preprint arXiv:2204.01691 (2022).
Li, Shuang, et al. “Pre-trained language models for interactive decision-making.” Advances in Neural Information Processing Systems 35 (2022): 31199-31212.
Lin, Jessy, et al. “Learning to model the world with language.” arXiv preprint arXiv:2308.01399 (2023).